Lecture automatisée d’une carte grise
Introduction
Nous avons pu voir dans un précédent billet intitulé « Un peu d’analyse et de traitement de l’image » que l’analyse et le traitement de l’image peuvent être appliqués au monde de l’assurance. Nous avons aussi vu qu’il existait pleins d’autres manières de les intégrer, c’est pourquoi nous allons parler ici de la lecture de carte-grise envoyée par un assuré.
On partira du principe que la carte pourra être prise en photo sans contraintes particulières (dans la limite du raisonnable bien sûr). Ce billet va donc se découper comme suit :
- Détection de points d’intérêts
- Correspondance et redressement
- Suppression de l’arrière-plan
- Segmentation et lecture des informations
Préambule
Petit disclaimer avant de commencer : toutes les images de carte-grise sont celle d’une carte spécimen. Toute correspondance avec de vraies informations serait totalement fortuite.
De plus, ce billet ne se concentre que sur une méthode pour récupérer les informations de la carte.
Pour ce faire, nous allons utiliser le langage Python, la bibliothèque de traitement d’image OpenCV et l’OCR (Optical Character Recognition) Tesseract maintenu par Google.
![]()
Python 3.10
![]()
Version 4.6
![]()
Version 5.1
Redressemment de l'image

Exemples de photo pouvant être analysée
Avant de pouvoir redresser l’image, il nous faut une carte-grise modèle. C’est grâce à elle qu’on pourra ensuite récupérer les informations aux bons endroits. L’avantage de ces cartes est qu’elles sont normées, ainsi, uniquement les informations sont différentes. Avec deux trois coups de photoshop, on peut les enlever et obtenir le résultat visible sur la droite. Il est bon de noter que l’arrière-plan de l’image a aussi été enlevé pour éviter de quelconque bruit parasite.
Le premier problème que l’on rencontre est le sens de la prise de vue de l’image. Comme nous n’avons pas imposé de contraintes pour la prise de photo, nous pouvons récupérer la carte-grise un peu sous n’importe quel sens. Or, Tesseract (l’OCR) n’est pas très friand d’images ne contenant pas de texte bien orienté (droit et avec un sens de lecture allant de la gauche vers la droite).
Vous trouverez un exemple d’image à lire ci-contre.
C’est pourquoi la première étape de l’analyse de la carte-grise consiste à redresser l’image et réadapter par la même occasion ses proportions. Pour cela, nous allons utiliser la correspondance de points d’intérêts.

Modèle de carte-grise
Détection des points d’intérêts
La première étape consiste donc à détecter les points d’intérêts sur l’image source et sur le modèle. Pour cela, nous allons utiliser l’algorithme SIFT (Scale Invariant Feature Transform) de David Lowe. Cette étape va aussi nous permettre de calculer les descripteurs de chaque points qui nous aideront pour l’étape suivante.

Points d’intérêts (en vert) sur l’image source et le modèle
Correspondance des points d’intérêts
Une fois les points et leurs descripteurs calculés, on applique le calcul de la correspondance en utilisant l’algorithme d’approximation des k plus proches voisins. Ici nous avons utilisé FLANN (Fast Library for Approximate Nearest Neighbors) de OpenCV pour calculer les correspondances entre les points d’intérêts de l’image et ceux du modèle en se basant sur les descripteurs.
On applique ensuite un seuil sur la distance séparant chaque voisin ce qui nous permet de retirer les points peu similaires.
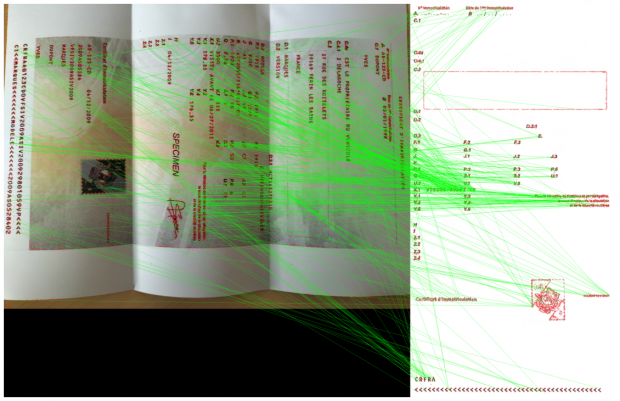 Correspondance des points d’intérêts par algorithme des plus proches voisins
Correspondance des points d’intérêts par algorithme des plus proches voisins
Redressement de l’image
Une fois toutes les correspondances récupérées, on peut déduire la matrice homographique qui nous servira de passage de l’image source vers le modèle. C’est la multiplication de l’image par cette matrice qui va redresser la carte-grise.

Redressement de l’image par rapport au modèle
Suppression de l'arrière-plan
Ce qui nous intéresse dans la carte-grise est uniquement le texte. Toutefois, sa reconnaissance peut être gênée par la présence d’ombre ou par les dessins en arrière-plan. Il est donc intéressant de les retirer afin de ne pas être dérangé lors de la lecture des caractères.
Pour pouvoir ne récupérer que l’arrière-plan, on commence par appliquer une dilatation. Cette opération va nous permettre de supprimer une grande partie du texte (le texte étant en noir, il va être remplacé par les couleurs de fond. On fait suivre la dilatation par l’application d’un filtre médian qui enlèvera les résidus (le bruit) qui a pu rester après l’opération. On se retrouve donc avec l’arrière-plan de notre image. Il nous suffit ensuite de soustraire l’arrière-plan à l’image originale pour ne récupérer que le texte. On finit par appliquer un seuil pour retirer de potentiels bruits en fond.

Suppression de l’arrière-plan de la carte-grise
Lecture des champs
La dernière étape consiste à lire les champs de la carte-grise. L’avantage du redressement est que l’on connaît l’emplacement de chaque information. Il nous faut donc les extraire et les faire lire par l’OCR. Celui que nous utilisons est Tesseract, un OCR conçu par Hewlett Packard dans les années 90 puis maintenu par Google. Il a l’avantage d’être gratuit et open source mais a certaines limitations que nous verrons par la suite.
Pour extraire les informations, on rogne l’image suivant ce que l’on souhaite récupérer. Dans notre exemple, voici les champs que nous récupérons :

Informations extraites et lues de la carte-grise
Tesseract nous retourne alors ces résultats :

Résultats de Tesseract sur chaque information
Validation des résultats
Comme on peut le constater, Tesseract est sujet aux erreurs surtout en ce qui concerne les polices admettant du serif (empâtements), ce qui est le cas de la police utilisée sur les cartes-grises. Il existe plusieurs solutions pour ce problème :
La première consiste à entraîner Tesseract (qui est un réseau de neurones) sur la police à étudier, cependant :
- La police n’est pas récupérable facilement, elle a été créée par l’administration française pour empêcher les contrefaçons.
- La carte-grise a en fait 2 polices de caractères, une pour les informations, une autre pour les codes des champs.
La deuxième solution serait de ne pas utiliser Tesseract mais un autre réseau de neurones qui pourrait être entraîné sur des cartes-grises ce qui faciliterait leur reconnaissance.
La troisième consiste à dire à Tesseract de ne reconnaître qu’une certaine liste de caractères (whitelist). Ainsi, pour reconnaître les caractères d’une plaque d’immatriculation, uniquement les caractères « ABCDEFGHIJKLMNOPQRSTUVWXYZ-1234567890 » sont utiles. Cela nous permet donc d’éviter de possibles confusions.
Et enfin une autre solution serait de calculer la distance de Levenshtein sur chaque champ en les comparant avec leur valeur récupérée en base de données. La distance de Levenshtein permet de calculer la différence entre deux chaînes de caractères. Elle est égale au nombre minimal de caractères qu’il faut modifier (insérer, remplacer ou supprimer) pour passer d’une chaîne de caractères à l’autre.
Pour finir
Voici à quoi pourrait correspondre un outil de lecture de carte-grise. Pour améliorer les résultats, il pourrait être intéressant, entre autres, de faire varier certains paramètres tels que la forme du modèle, passer à un algorithme de recherche de voisins brute-force (test de tous les cas possibles).
L’avantage de cette méthode vient de sa polyvalence. On peut alors lire n’importe quelles informations du moment qu’on change le modèle et les positions des informations sur le modèle.
À propos de l'auteur. Vincent Commin est Alternant au sein du DARVALab et en Master 2 Conception Logicielle à l'université de Poitiers. Passionné par la recherche, le développement et l'intégration de nouvelles solutions et technologies au service des développeurs et des utilisateurs.